

Quale sistema di visione usare per la propria applicazione robotizzata?
Quello che un robot può e non può vedere
Negli ultimi anni, i sistemi di visione computerizzata sono diventati molto avanzati e, al contempo, anche molto intuitivi, tanto da rendere facile dimenticare che sono ancora molto rudimentali rispetto alla visione umana.
Con nostro “personale sistema di visione” siamo in grado di riconoscere lo stesso oggetto in condizioni notevolmente diverse. Ci possono essere cambiamenti di illuminazione, di struttura, di dimensioni, di distanza, ombreggiatura, colore, movimento, e molte altre proprietà visive che cambiano ma noi siamo sempre in grado di riconoscere l’oggetto in qualsiasi contesto venga visto.
Questa interessante tesi sulla robotica, che dimostra la necessità scientifica di avere sistemi autonomi affidabili per la rilevazione e classificazione degli oggetti, spiega che il nostro sistema visivo è così buono anche perché “l’hardware sull’umano medio è eccellente: è dotato di telecamere stereo a colori ad alta risoluzione con la pre-elaborazione integrata“. E’ efficace anche perché “queste informazioni di basso livello vengono combinate in qualche modo con informazioni di alto livello sulla conoscenza di ciò che appare (l’oggetto) e generalmente di come sembra (la percezione del “modello”).”
Facendo un esempio, noi siamo in grado di riconoscere che un oggetto è un’automobile anche se non abbiamo mai visto prima il modello esatto di quell’auto, perché siamo in grado di generalizzare ciò che assomiglia a un’auto. Invece un robot può vedere solo ciò che è effettivamente ritratto nell’immagine.
La visione robotica computerizzata
 Anche i sistemi di visione robotica utilizzano i modelli per rilevare oggetti noti, tuttavia non sono non sono certamente avanzati come i modelli utilizzati dal sistema visivo umano.
Anche i sistemi di visione robotica utilizzano i modelli per rilevare oggetti noti, tuttavia non sono non sono certamente avanzati come i modelli utilizzati dal sistema visivo umano.
I moderni sistemi di visione utilizzano spesso combinazioni avanzate e diverse tecniche di visione artificiale, ed alcuni risultano incredibilmente robusti ai cambiamenti del contesto in cui si trovano gli oggetti da rilevare, come l’illuminazione, la distorsione, il basso contrasto e molti altri problemi che affliggono tipicamente le messe a punto dei sistemi di visione.
Molti sistemi di visione robotica sfruttano la tecnica del template matching, dove si tratta di prendere un modello dell’immagine dell’oggetto e di individuare le aree simili rispetto all’immagine rilevata, confrontando direttamente le immagini in scala di grigi o ricorrendo al metodo di rilevazione di bordi dell’immagine, come descritto più avanti.
Gli algoritmi di matching dei modelli si occupano di rilevare la posizione dell’oggetto all’interno dell’immagine corrente, rilevando anche oggetti ruotati, oggetti in scala e persino oggetti con una distorsione o un occlusione. Spesso è anche molto semplice impostare l’immagine modello: è sufficiente mettere l’oggetto sotto una telecamera e inquadrarlo.
Il sistema di visione robotica salverà l’immagine modello e la userà come riferimento per trovare l’oggetto nelle immagini future.
L’algoritmo di template matching andrebbe quindi ad analizzare l’immagine corrente della telecamera per individuare le aree che sono simili al modello salvato.
 Questo approccio di base potrebbe essere però piuttosto limitato, risultando poco robusto alle variazioni incoerenti della luminosità all’interno dell’immagine.
Questo approccio di base potrebbe essere però piuttosto limitato, risultando poco robusto alle variazioni incoerenti della luminosità all’interno dell’immagine.
Per migliorarlo si potrebbe utilizzare un sensore di visione con una fonte di luce integrata ed ottenere una luce coerente per agevolare il riconoscimento.
Scopri Camera Vision System di Robotiq, il sistema plug&play di visione specifico per i robot Universal Robots.
Una forma leggermente più avanzata di template matching consiste nell’estrarre i bordi dell’immagine dall’immagine modello e confrontare lo schema con i bordi dell’immagine rilevata dalla telecamera, intesi come i confini tra aree chiare e scure.
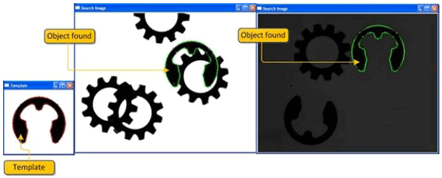
Il rilevamento dei bordi è il primo passo per molti sistemi di visione artificiale e sicuramente questo è un approccio più robusto ai cambiamenti d’illuminazione, anche se l’algoritmo può ancora essere ingannato da ombre molto marcate, dalla presenza di linee sullo sfondo e dalla distorsione.
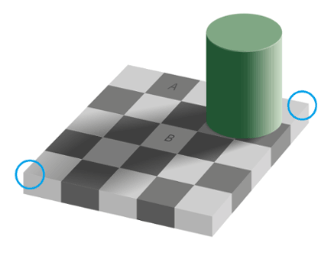 Nell’immagine a lato è riportata un’illusione ottica, che dimostra come il nostro sistema visivo è bravo a correggere i cambiamenti di luce. Le zone indicate con A e B hanno esattamente la stessa tonalità di grigio, ma vediamo B come più chiaro perché il nostro cervello corregge l’ombra proiettata dal cilindro, mentre un sistema di visione computerizzata vedrebbe gli stessi colori esattamente uguali (verifica tu stesso!).
Nell’immagine a lato è riportata un’illusione ottica, che dimostra come il nostro sistema visivo è bravo a correggere i cambiamenti di luce. Le zone indicate con A e B hanno esattamente la stessa tonalità di grigio, ma vediamo B come più chiaro perché il nostro cervello corregge l’ombra proiettata dal cilindro, mentre un sistema di visione computerizzata vedrebbe gli stessi colori esattamente uguali (verifica tu stesso!).
Tuttavia, un algoritmo per il rilevamento dei bordi sarebbe in grado di rilevare le linee, rilevando i pixel in cui la luminosità cambia bruscamente e confrontandoli con i loro vicini. In questo caso, il rilevamento dei bordi consentirebbe all’algoritmo di correggere le incongruenze d’illuminazione e disegnare così le linee della scacchiera.
In generale, un algoritmo di rilevamento del bordo potrebbe avere qualche problema. Considerate le linee intorno al bordo della scacchiera, lungo i bordi inferiori sinistro e destro (indicati dai cerchi). Le differenze di luminosità tra le superfici sono minime, quindi l’algoritmo non potrebbe non rilevarle come bordi. Il grigio in entrambe le facce è quasi lo stesso e in un angolo ha solo 3 livelli di luminosità (su 255) di differenza. Noi vediamo un bordo perché guardiamo l’intera forma, ma l’algoritmo non sarebbe in grado di farlo. Analogamente, un algoritmo può erroneamente rilevare un bordo lungo il centro del cilindro, in corrispondenza della sua ombra.
Queste considerazioni sono solamente una piccola introduzione al ben più ampio, complesso ed elaborato tema della visione artificiale, impossibile da affrontare in un semplice articolo di blog!
In sintesi potremmo dire che durante la progettazione e configurazione di un sistema di visione per un robot, è importante prestare attenzione a ciò che è effettivamente presente nell’immagine piuttosto di ciò che il noi siamo in grado di conoscere ad occhio nudo.
Quale sistema di visione usare per la propria applicazione?
Per progettare sistemi di visione robotica e ottenere il massimo dagli algoritmi di interpretazione dei modelli di corrispondenza, occorre sempre ricordare che immagini chiare, con bordi ben definiti e un’illuminazione costante, miglioreranno sicuramente il rilevamento dei vostri oggetti.
 Quindi, ricordando come funziona la visione artificiale, durante la progettazione di configurazioni per la visione computerizzata, si deve dimenticare ciò che gli occhi vedono e iniziare a pensare a quello che la fotocamera e gli algoritmi in realtà rilevano.
Quindi, ricordando come funziona la visione artificiale, durante la progettazione di configurazioni per la visione computerizzata, si deve dimenticare ciò che gli occhi vedono e iniziare a pensare a quello che la fotocamera e gli algoritmi in realtà rilevano.
Anche se si sta utilizzando un sistema con funzionalità avanzate, si progetterà una configurazione molto più robusta se si immagina che il sistema sia basico.
Il nostro cervello infatti è così abituato a vedere immagini in 3D o 2D che ci induce a pensare che questi siano i sistemi di visione ideali anche per l’automazione industriale, per i robot collaborativi ad esempio.
Sensore 1D: in presenza di un trasportatore
Se la vostra necessità è solo quella di misurare una parte che si muove su un trasportatore, uno scanner laser o una fotocamera a scansione lineare sarebbe sufficiente. Basterebbe installarli perpendicolarmente al movimento della parte, sul lato o sulla parte superiore del trasportatore.
Gli scanner utilizzeranno una triangolazione laser per effettuare le misurazioni, proiettando un punto o un fascio laser e riflettendolo a sua volta verso il sensore dello scanner. L’utilizzo del laser ci darebbe un grande aiuto sui problemi di illuminazione perche il laser funzionerebbe anche a luci spente. Si possono trovare maggiori informazioni sulle varie misurazioni possibili e il modo corretto con una ricerca web.
Se è necessario ispezionare la superficie di una parte che si muove su un trasportatore, una fotocamera a scansione lineare sarebbe preferibile, installandola sulla parte superiore del trasportatore. Si potrebbero così raccogliere le “linee delle immagini”, unirle in modo da ottenere un’immagine 2D, e analizzarle come desiderato. La telecamera lineare è simile a una fotocamera 2D, ma con un sensore che ha una sola fila di pixel fotosensibili.
 Usare una telecamera lineare, combinata al movimento del trasportatore, ha un enorme vantaggio rispetto a una fotocamera 2D: poiché la parte si muove, si avrebbe bisogno di ridurre il tempo di esposizione (quantità di tempo in cui la telecamera raccoglie dati) per evitare il mosso. In questo modo si avrà un’immagine più scura, ma sarà sufficiente correggere l’illuminazione locale per correggerla.
Usare una telecamera lineare, combinata al movimento del trasportatore, ha un enorme vantaggio rispetto a una fotocamera 2D: poiché la parte si muove, si avrebbe bisogno di ridurre il tempo di esposizione (quantità di tempo in cui la telecamera raccoglie dati) per evitare il mosso. In questo modo si avrà un’immagine più scura, ma sarà sufficiente correggere l’illuminazione locale per correggerla.
Utilizzando invece una macchina fotografica in 2D sarebbe necessario illuminare a sufficienza tutta la zona.
Se si utilizza una macchina fotografica a scansione lineare, inoltre, si potrebbe ottenere facilmente una luce uniforme, concentrandola solo in una zona limitata, operazione che sicuramente risulterà ancora più facile per le superfici piccole.
Non dobbiamo dimenticare che poi dobbiamo essere in grado di eliminare le imprecisioni date dalla fluttuazione di velocità del nastro trasportatore e delle imperfezioni della sua superficie.
Infine, utilizzando le immagini della telecamera lineare e la velocità del trasportatore come parametri, è possibile “cucirle” insieme ed ottenere effettivamente delle immagini 2D (anche se in realtà è un tipo di un’immagine a larghezza infinita). Si possono trovare maggiori informazioni su questo processo qui.
Sensore 2D: per la maggior parte delle applicazioni
Andiamo subito alla domanda fondamentale: quando serve una camera 2D? Quando l’immagine non è in movimento lineare, quando devo solo analizzare una superficie e posso dimenticarmi della porfondità. Questa è la soluzione della Camera Robotiq, il sistema di visione plug&play dall’integrazione semplice e intuitiva.
Se questo è il vostro caso, un’altra domanda è necessario porsi: avete bisogno di una telecamera a colori o una in bianco e nero sarebbe sufficiente?
Il nostro cervello è così abituato a vedere a colori, che si tende a pensare che ne abbiamo bisogno anche per la nostra macchina fotografica. E’ molto più semplice, però, analizzare immagini in bianco e nero.
Utilizzando una telecamera a colori avremmo più dati, ma …servono davvero?
Con una macchina fotografica in bianco e nero avremmo comunque molteplici sfumature di grigio con cui lavorare e saremmo in grado di ridurre i tempi del processo di lavorazione e ridurremmo anche il tempo di trasferimento dei dati e della loro memorizzazione.
Un’altra cosa da tenere presente sulle macchine fotografiche 2D: alcune telecamere hanno dei sensori che catturano l’immagine e consentono di trasferirla a un computer esterno per un’elaborazione completa mentre altre fotocamere, le cosiddette telecamere intelligenti o smart camera, hanno sensore e processore integrati, proprio come la soluzione Camera Robotiq. Se avete bisogno di elaborare delle immagini di base, per le operazioni di pick & place per esempio, questo tipo di camera sarà probabilmente sufficiente e non sarà necessario aggiungere un computer a parte per farlo.
Oltre alla camera e al processore di elaborazione serve anche un’ottica. Si potrebbe valutare uno di quei pacchetti ‘all-in-one‘, che includono la fotocamera, l’obiettivo e il processore, oppure si potrebbe valutare la possibilità di acquistare gli oggetti separatamente. In questo caso, occorre selezionare una lente adeguata, determinando quali dimensioni del campo visivo e che risoluzione siano necessarie, ma anche quanto sarà lontana la fotocamera dall’oggetto ispezionato.
A seconda dell’applicazione in uso, potete farvi consigliare dal vostro rivenditore di fiducia verso un obiettivo e/o una dimensione sensore adeguati ma dal momento che è sempre meglio avere una conoscenza di base è utile sapere questa semplice regola per scegliere una lente da usare con una macchina fotografica in 2D.
Seguendo le regole dei triangoli simili, è possibile usare questa formula:
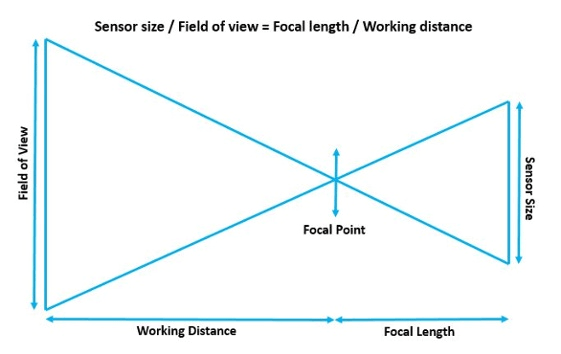
Dimensioni del sensore (sensor size): dimensione effettiva del sensore CCD all’interno della fotocamera.
Campo visivo (field of view): La dimensione fisica della zona che deve essere inquadrata dalla vision camera.
Lunghezza focale: la distanza della convergenza della luce (25mm, 50mm, ecc.). La lunghezza focale è inversamente proporzionale al campo visivo, così un’immagine scattata con un obiettivo di 50mm sarà più ingrandita rispetto ad una fatta con una lente 25 mm.
Distanza di lavoro: La distanza fisica dei sensori rispetto all’oggetto che si desidera guardare.
Sapendo quindi il campo visivo necessario e la dimensione del sensore si potrà determinare la tipologia di obiettivo necessario e successivamente definire la posizione di installazione della camera secondo sal formula Wd=Fl*(Fw/Ss).
Sensore 3D: nel caso di reverse engineering o metrology
Per altri tipi di applicazioni, come il reverse engineering o metrology, potrebbe essere necessario uno scanner 3D.
Gli scanner 3D disponibili sul mercato utilizzano varie tecniche: triangolazione laser, illuminazione strutturata, eccetera. La scansione in 3D vi lascerà con un enorme carico di dati da elaborare assicuratevi quindi di aver bisogno di tutte queste informazioni prima di acquistare uno scanner 3D.
Sarà inoltre necessario scegliere lo scanner appropriato in base all’applicazione che avete in mente: alcuni scanner sono molto precisi nelle misurazioni, ma il loro campo visivo è di pochi centimetri di larghezza, mentre altri scanner eseguono la scansione di grandi aree in un momento, ma sono sicuramente meno precisi nelle misurazioni.
Concludendo, per poter scegliere un sistema di visione adeguato, è sempre necessario considerare anche l’applicazione. Sarà necessario impiegare sensori 1D, 2D o 3D?
I sensori e i sistemi di visione, aggiuntivi o integrati, risultano particolarmente utili e vantaggiosi in robotica per le attività di pick and place.
Continuate a seguirci, nei prossimi articoli spiegheremo come implementare un pick&place di oggetti con robot collaborativi grazie ai sensori di visione!





